大規模言語モデルを活用するために知っておきたいこと〜LLMの抱える危険性から社内活用まで〜
皆様、大変ご無沙汰しております。調べ物をしていたら、自分がブログを書いていたことをふと思い出しました。多くの方に読んでいただいているようなので、備忘録も込めて、ブログを再開しようと思います。
今回は、大規模言語モデルについてのお話です。昨今、ChatGPTを代表とする大規模言語モデル(LLM)が注目を集めています。私はとある企業様から依頼を頂き、”大規模言語モデルの活用”について講演させて頂きました。今回は、その講演内容の資料を公開しますので、ぜひ読んでいただけると幸いです。
サマリー
- LLMは多くのリスクを抱えており、活用する際には、以下のリスクを考慮する必要がある
- Hallucinations
- Harmful content
- Disinformation and influence operations
- Privacy
- Cybersecurity
- 上記のリスクを低減するために、OpenAI等のLLMサービス提供会社は以下の対策を実施している
- Reinforcement Learning from Human Feedback(RLHF)
- Moderation API
- プロンプトインジェクション対策
- 各社がLLMを活用するためには、自社が置かれている状況をきちんと把握し、自社にあったサービス等を選定・活用する必要がある
- 機密情報を扱っており、かつ、クラウドサービスが利用不可の場合は、自社独自のLLM構築が必要
講演資料URL
講演内容の詳細はこちらから参照ください。
DevOpsとSREについて、簡潔にまとめてみた
DevOpsとSREってよく聞くけど、その違いってなんだっけ、と思っている方は多いのではないかなと思い(私もそのうちの一人です)、その違いについてまとめてみました。
サマリー
・DevOpsはアジャイル型の開発手法の1つで、開発チームと運用チームが連携することで、品質を落とすことなく、開発速度を上げるために用いられる。
・SREは「自動化に費やす時間を確保する」、「顧客へのサービスレベル目標を立て、計測し、それを開発チームと運用チームで共有することで連携を促す」という特徴を持ったDevOpsを実現する手法である。
従来の開発の問題点
従来、ウォーターフォール型と呼ばれる顧客の要件をきっちりと固め、開発するスタイルが一般的でした。しかし、このウォーターフォール型では、顧客の要望が変化した際に対応できないという問題点があります。この問題点を解決するために、アジャイルと呼ばれる開発手法が採用されるようになってきました。アジャイルでは、「計画→設計→実装→テスト」といった開発工程を機能単位の小さいサイクル(スプリントと呼ばれます)で繰り返すのが最大の特徴です。これにより、顧客の要望に柔軟に対応可能となります。環境の変化が激しい昨今にマッチした開発手法と言えます。
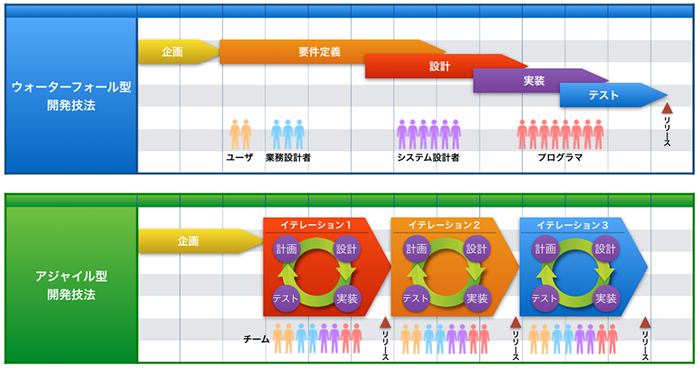
DevOpsとは
DevOpsはアジャイル開発手法の1つで、ソフトウェアやシステムの開発チームと運用チームの連携によって、品質を落とすことなく、サービス改善のサイクルを早めることを目的としています。従来であれば、開発チームと運用チームは分かれて作業することが一般的でした。この障壁を取り除き、1つの統合されたチームとして作業することで、開発スピードを上げようとするのが、DevOpsの基本的な考え方です。

SREとは
DevOpsと似た概念として、Site Reliability Engineering(SRE)という考えが普及してきています。DevOpsはあくまで、「思想」であるのに対し、SREは「その実現方法」と捉えるとわかりやすいかと思います。SREの基本は以下の3つに集約されます。
トイル(Toil)の制限
トイルとは人手で繰り返し行う自動化の余地がある作業のことです。手作業の時間を「作業時間全体の50%」までに制限して、残りの50%を自動化やサービスの質を向上させるために活用させます。
SLI・SLOによる目標定量化
SLI(Service Level Indicators)顧客へのインパクトをサービス・レベルとして計測するための指標、SLO(Service Level Objective)SLIに基づいて計測されるサービス・レベルの目標値やその範囲を指します。
エラーバジェットの適切な設定
エラー バジェットは、ユーザーが不満を感じ始めるまでの一定の期間にサービスで累積できるエラーの量です。可用性の目標(SLO)を99.9%とすると、エラーバジェットは0.1となります。このエラーバジェットに達するまで、エラーが許容されます。あまりに高い目標を置きすぎると、そこに時間を無駄に割くことになるので、適切なエラーバジェットを設定することが重要です。そして、エラーバジェットという共通の目標を運用側と開発側で共有することで、協力的な関係を築くことができます。
適用事例
国内での適用事例は以下の通りです。
メルカリ
個人間でのやり取りが頻繁に発生するアプリのため、ダウンタイムの削減を目的として2015年、SREを導入しています。これにより、チームを横断した管理体制と信頼性の向上、品質改善を可能にしています。
ヌーラボ
「各サービスを開発する課」とは独立した形で「SRE課」を発足させています。この体制は自らが担当するプロダクトを抱えながらも、他チームとも横断的に連携することを目的として作られました。
参考文献
・SREとは何か?DevOpsと何が違う?ガートナーが解説する運用管理変革の現実解 |ビジネス+IT
・DevOps とは? - DevOps と AWS | AWS
・メンテナンスの時間枠がエラー バジェットに与える影響 - SRE のヒント | Google Cloud Blog
・アジャイル開発 ~顧客を巻き込みチーム一丸となってプロジェクトを推進する~ (前編): コラム | NECソリューションイノベータ
・アジャイル開発とは? 特徴とメリット・デメリット、スクラムまで徹底解説 | モンスターラボ DXブログ
・Lowe’s が Google SRE プラクティスで顧客の要求に応えている方法 | Google Cloud Blog
最近話題の"Diffusion Model(拡散モデル)"について、簡潔にまとめてみた
OpenAIが先日発表したGLIDEにDiffusion Moldelが使用されているとのことで、最近話題のDiffusion Model(拡散モデル)について、まとめました。
サマリー
・Diffusion Model(拡散モデル)は、元データにノイズが徐々に付加されていき、最終的にガウシアンノイズとなるという前提を置き、その逆のプロセスをモデル化することでデータを生成する。
・GANやVAEよりも高品質の画像を生成することに成功しており、様々な分野への応用が期待される。
生成モデルとは
生成モデルを使用することで、データ(ex. 画像)の生成プロセスをモデル化し、ノイズ等から新たなインスタンスを生成することが可能です。下記の図は、生成モデルによって生成された画像です。もはや本物としか思えないほど、精巧な画像を生成できています。

代表的な手法として、GAN・VAE・Flowがあります。Diffusion Modelはこれらの生成モデルと同等、或いはそれ以上に精巧にデータ生成できることが、昨今の研究で判明しています。
Diffusion Model(拡散モデル)とは
Diffusion Modelはノイズからスタートし、徐々にノイズを除去していくことで、データを生成するモデルです。下記の図では、からスタートし、T回のノイズ除去ステップを踏むことで、顔画像
を生成しています。もちろん、どのようにノイズを除去すればよいのか、言い換えるならば、どのような過程でノイズが付与されたのか、ということが分からなければ、データを生成することはできません。ノイズを付与していく過程をForward diffusion process、除去していく過程をReverse diffusion processと呼びます。以下、この2つのプロセスについて、考えていきましょう。
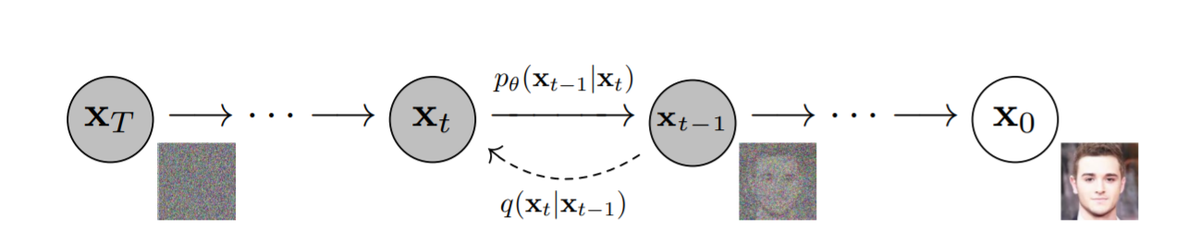
Forward diffusion process
このプロセスは、状態にガウシアンノイズを付与することで、次の状態
に遷移させるプロセスです。つまり、このプロセスはノイズの強さを
とすると、以下のように表現できます。なお、初期状態
は
からサンプルされているとします。
これは、任意のステップの状態
が前の状態
の関数で表現できるということです。つまり、これを
回繰り返すことで、
を初期状態
で表現できます。なお、
と定義しています。
\begin{aligned}
\mathbf{x}_t
&= \sqrt{\alpha_t}\mathbf{x}_{t-1} + \sqrt{1 - \alpha_t}\mathbf{z}_{t-1} & \text{ ;where } \mathbf{z}_{t-1}, \dots \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \\
&= \sqrt{\alpha_t \alpha_{t-1}} \mathbf{x}_{t-2} + \sqrt{1 - \alpha_t \alpha_{t-1}} \bar{\mathbf{z}}_{t-2} & \text{ ;where } \bar{\mathbf{z}}_{t-2} \text{ merges two Gaussians } \\
&= \dots \\
&= \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\mathbf{z} \\
q(\mathbf{x}_t \vert \mathbf{x}_0) &= \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t)\mathbf{I})
\end{aligned}
Reverse diffusion process
ノイズを除去していくプロセスをモデル化できれば、状態からデータを生成できます。つまり、Forward processの逆プロセスである
を表現できれば良いということです。
が十分小さいとすると、
はガウス分布に従います。これをパラメータ
のニューラルネットワーク
で近似します。
は、このままでは非常に扱いにくいので、
で条件付けします。この
もガウス分布に従うと仮定し、平均及び分散を何かしらの形で表現することを目指します。詳細は割愛しますが、ベイズの定理を用いて、平均及び分散は以下となります。
\begin{aligned}
\tilde{\boldsymbol{\mu}}_t &= {\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbf{z}_t \Big)} \\\tilde{\beta}_t &= 1/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) = \frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t \\
\end{aligned}
学習
上記を踏まえて、Diffusion Modelを学習させるために必要な損失関数を考えます。詳細は割愛しますが、クロスエントロピーの最小化、或いはVAEと同様に負の対数尤度の最小化を目指すことで、損失関数は以下となります。なお、はカルバックライブラーダイバージェンスを表しています。
\begin{aligned}
L_\text{VLB} &= L_T + L_{T-1} + \dots + L_0 \\
\text{where } L_T &= D_\text{KL}(q(\mathbf{x}_T \vert \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_T)) \\
L_t &= D_\text{KL}(q(\mathbf{x}_t \vert \mathbf{x}_{t+1}, \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_t \vert\mathbf{x}_{t+1})) \text{ for }1 \leq t \leq T-1 \\
L_0 &= - \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)
\end{aligned}
の最小化は、2つのガウス分布の平均及び分散の差分の最小化と等しくなります。分散を固定のパラメータとすると、ガウス分布の平均の差を小さくするように学習すれば良いことになります。
※分散を固定のパラメータとせず、学習可能なパラメータとしたほうが良い結果が得られるとの実験結果が出ています。詳細はこちらをご覧ください。
応用例
画像生成
DhariwalとNicholはDiffusion Modelを使用して、BigGANと呼ばれる非常に高品質の画像と同等の品質の画像を生成することに成功しています。

条件付き画像生成
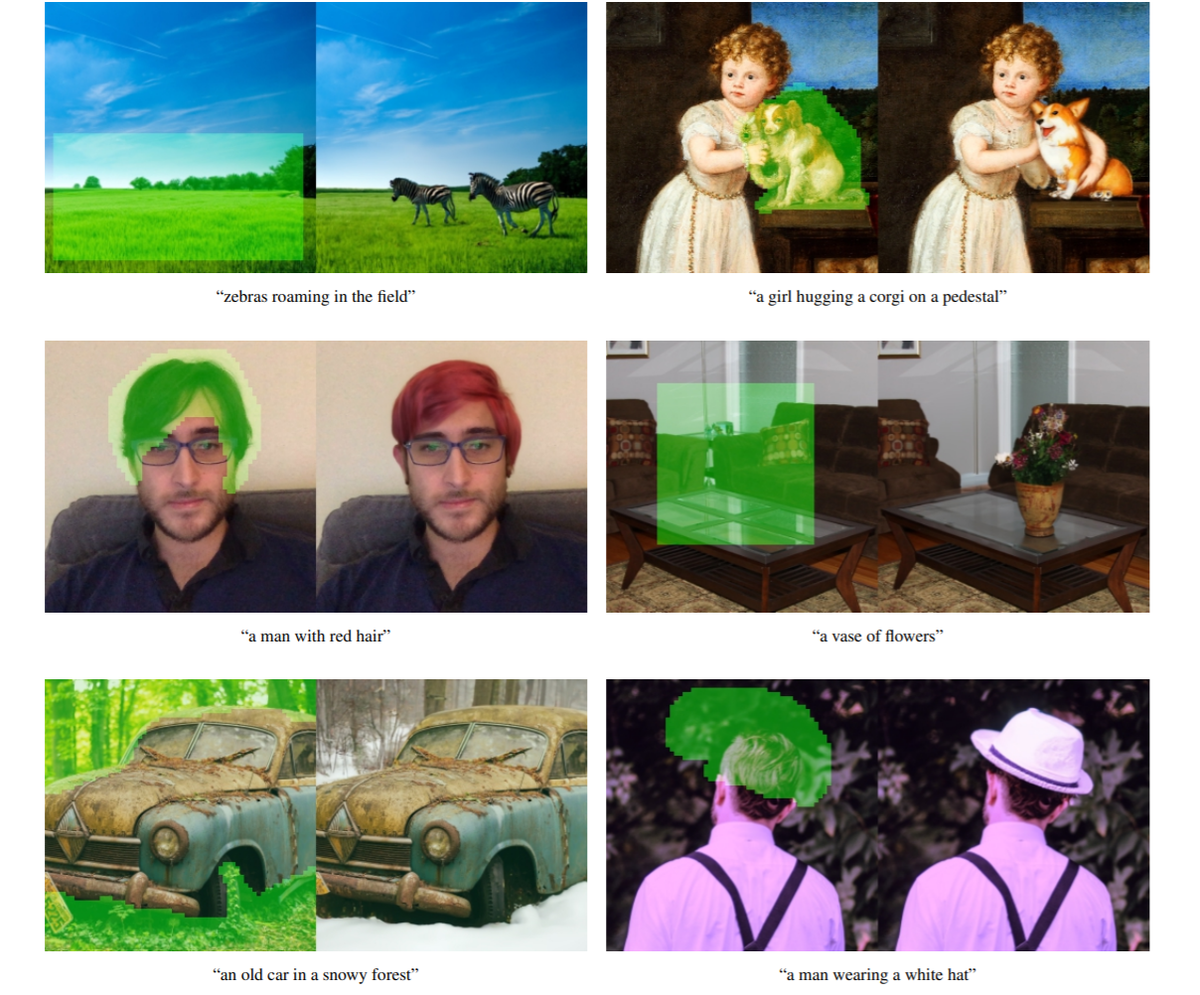
DhariwalとNicholらはテキストに沿った高品質の画像を生成することに成功しています。学習データセットに含まれないような画像を生成できており、モデルが人間のように言葉を理解し、それを画像に反映させているようにも見えます。

画像変換
DhariwalとNicholらは上記と同様のDiffusion Modelを使用して、指定した個所をテキストに沿って変換するタスクを実施しています。結果を見ると、非常に高精度に画像を変換できていることが分かります。
参考文献
・Inject Noise to Remove Noise: A Deep Dive into Score-Based Generative Modeling Techniques
・Denoising Diffusion Probabilistic Models
・Diffusion Models Beat GANs on Image Synthesis
・GLIDE: Towards Photorealistic Image Generation and Editing with
Text-Guided Diffusion Models
コンテナとその周辺技術について、簡潔にまとめてみた
昨今、コンテナという言葉はよく耳にするものの、個人的にあまり良くわかってないなと感じたため、コンテナとその周辺技術についてまとめてみました。
サマリー
・コンテナは、1つのサーバー上に作られた論理的な区画であり、従来の仮想化技術と比べて高速な動作や迅速なリリースに対応可能な技術である。
・複数のコンテナを運用する場合、管理の手間が非常に煩雑となる。その解決手段として、コンテナオーケストレーション技術がある。
・コンテナと相性の良いマイクロサービスが抱える「障害連鎖」や「通信の安全性」といった問題を解決する技術として、サービスメッシュ技術がある。
コンテナとは
コンテナとは、仮想化技術の1つで、1台のサーバーの上に作られた論理的な区画を指します。1つのOSの上で、仮想的な区画であるコンテナを複数提供できます。従来の仮想化技術と並べて図に示すと、以下となります。左が従来の仮想化技術、右がコンテナを使用したものを表しています。従来の仮想化技術としてVM Ware、コンテナ技術としてDockerなどが代表的です。

従来の仮想化技術とコンテナは何が異なるのでしょうか。アプリケーション(以下、アプリ)を動かす際には、以下の工程が必要です。
【従来の仮想化技術】ホストOS ⇒ 仮想化ソフトウェア ⇒ ゲストOS ⇒ アプリ
【コンテナ】ホストOS ⇒ アプリ
つまり、コンテナの場合、仮想化ソフトウェア+ゲストOSを介した工程が不要です。アプリを動かすために、ホストOSを使用しています。より詳細にはホストOS内のカーネルを使用しています。
※カーネル:コンピューターの基本的な操作を行う機能を格納したライブラリ群
メリット
・高速な動作
アプリを動かすための工程が少なく、高速に動作する。
・高頻度のリリースに対応可能
コンテナを使用することで、HWやOSと切り離して開発できるため、開発環境で作成したものを、本番環境のような異なる環境に適用することが容易である。
デメリット
・同一のOSを利用する必要
同一のOS上で動作させる必要があり、アプリ毎に個別にOSを選択できない。
・コンテナ間の分離レベルが低い
コンテナ間の分離レベルが低く、セキュリティ要件が厳しい業界や企業には適用しにくい。
周辺技術
・コンテナオーケストレーション
マルチホストで構成されたクラスター環境で動作させる場合、ホストOS間のネットワークやストレージ等の管理が必要となり、人手による運用が非常に煩雑となります。この問題を解決する技術がコンテナオーケストレーションです。代表的なツールとして、Kubernetesがあります。
・サービスメッシュ
コンテナ技術と非常に相性が良い開発手法として、マイクロサービスがあります。これは、個々のアプリをなるべく疎になるように開発する手法で、アプリのリリース速度を早めることが可能など、変化の激しい現代に適しています。一方で、以下のような課題を抱えています。
・障害の連鎖
・障害が起きているもしくはレスポンスタイムが悪いサービスの特定
・マイクロサービス間の通信の安全性
これらの問題を解決する技術として、サービスメッシュがあります。サービスメッシュはサービス間通信を処理するソフトウェアで、アプリケーションに代わってネットワーク要求を処理します。代表的なツールとして、Istioがあります。
余談ですが、米空軍は戦闘機F-16にKubernetesとIstioを搭載したようです。これにより、AIなどの機能を柔軟にデプロイできるようになったとのことです。
参考文献
・【連載】世界一わかりみが深いコンテナ & Docker入門 〜 その1:コンテナってなに? 〜 | SIOS Tech. Lab
・注目を浴びる「Dockerコンテナ」、従来の仮想化と何が違うのか? | 東京エレクトロンデバイス
・コンテナオーケストレーションとは?仕組みやメリット、注目のツールについて徹底解説|サイバーセキュリティ.com
・DevOps、CI/CDパイプラインでもコンテナは大活躍! | Think IT(シンクイット)
・Istio入門 その1 -Istioとは?- - Qiita
・How the U.S. Air Force Deployed Kubernetes and Istio on an F-16 in 45 days – The New Stack
MITRE ATT&CKについて、簡潔にまとめてみた
サイバーセキュリティは、攻撃者目線で対策を検討・実施することが非常に重要です。攻撃者目線でセキュリティを検討する際に、良く使用されるMITRE ATT&CKについて、簡潔にまとめてみました。
サマリー
・MITRE ATT&CKは、サイバーキルチェーンと同様に攻撃者の振る舞いを理解するフレームワークです。
・ハッシュ値やIPアドレスといった変更しやすい痕跡ではなく、攻撃者が変更しにくい振る舞い(TTP)を理解することにつながり、有効なセキュリティ対策が可能となります。
・攻撃のシナリオ作成や、自社のセキュリティ対策の評価など様々な用途に使用可能です。
MITRE ATT&CKとは
MITRE ATT&CK(以下、ATT&CK)は、非営利組織のMITRE社が公表している攻撃者の戦術や使用する技術をまとめたナレッジベースのことです。セキュリティチームは、このフレームワークを活用することで、攻撃者がどのような戦術で、どのような技術を使用して攻撃してくるのか理解できます。いわゆる攻撃者のTTP(Tactics, Techniques, Procedure)の理解につながります。下記の図は、MITREが提供している戦術(Tactics)と、それに使われる技術(Techniques)をマトリクスで表したものです。横軸が戦術、縦軸が技術を表しています。

サイバーキルチェーンとの差異
攻撃者の振る舞いを理解するフレームワークとして、サイバーキルチェーンが有名です。サイバーキルチェーンは、「偵察」「武器化」「配送」の前段階を含めた一連の振る舞いをモデル化しています。一方、ATT&CKは攻撃者がターゲットのシステムに侵入した後の振る舞いをモデル化しています。

なぜ、注目されているのか
ATT&CKは攻撃者のTTPを理解するのに役立ちます。つまり、攻撃者が何を狙い、どのような戦術で、どのような技術を使うのか、理解するということです。TTPを理解すると、どのようなメリットが得られるのでしょうか。それには、下記に示す「痛みのピラミッド」という概念が役に立ちます。これは、攻撃者にとって対策されても痛みの小さいものから大きいものに並べたものです。例えば、攻撃者が使用しているIPアドレスをブロックしても、IPアドレス等を変えることは非常に簡単であるため、攻撃者にとって、対策されてもあまり痛みはありません。一方、攻撃者は使用する戦術を簡単には変更できません。変更するには、それだけの労力が必要となるからです。つまり、TTPを理解することは、攻撃に係る労力(ワークフォース)を高めることにつながり、結果として、効果的なセキュリティ対策につながります。

MITRE ATT&CKの利用方法
MITRE社は、以下のようにATT&CKを使用することを推奨しています。
- 攻撃の事前検証
・攻撃者の攻撃を想定するシナリオの作成ツールとして使用する。 - レッドチーム演習
・レッドチームプランを作成し、ネットワーク内に配置される特定の防御手段を回避するための運用を整理する。 - 行動分析の開発
・環境内の攻撃行動を検知する行動分析を行い、未知の手法を見つけ対応する手法の開発のためのテストツールとして使用する。 - 防御のギャップ評価
・攻撃者の戦術・技術のユースケースとして活用し評価に使用することで、既存のセキュリティ対策と現実の攻撃手法とのギャップを明らかにする。 - SOC(Security Operations Center)の成熟度評価
・SOCが攻撃の検知及び攻撃が成立した後の攻撃者侵入検知、分析、対応する事がどの範囲まで可能であるのかを測定するための測定値として使用する。 - サイバー脅威インテリジェンス(CTI)の強化
・攻撃者グループについての理解を深めるツールとして使用する。CTIに関するレポートは様々なベンダーが出しており、これらを補完する目的で使用する。
まとめ
MITRE ATT&CKはサイバーキルチェーンと同様に、攻撃者の振る舞いの理解に役立つフレームワークです。これを使うことで、より実践的なセキュリティ対策が可能となります。より詳しい議論は、参考文献をご覧ください。
参考文献
・今知るべきATT&CK|攻撃者の行動に注目したフレームワーク徹底解説
・MITRE ATT&CKフレームワークとは? | Splunk
”カオスエンジニアリング”について簡潔にまとめてみた
昨今、システムのレジリエンスを高めるための手法として、カオスエンジニアリングが注目を集めています。この記事では、カオスエンジニアリングについて、簡潔にまとめました。
■ サマリー
・カオスエンジニアリングは、システムに意図的に障害を発生させ、複雑なシステムの挙動を知ることで、耐障害性を高める開発手法である。
・サイバー攻撃が増加の一途をたどる中、攻撃を受けダウンしてもすぐに復旧するレジリエントなシステム作りが可能となる。
・システムの定常状態を定義し、現実世界で起こりうる障害を注入することで、システムの問題点を洗い出し、改善を実施する。
目次
- カオスエンジニアリングとは
- サイバーセキュリティとの関連性
- 基本手順
- 親和性の高い業界・システム
- 事例紹介
- まとめ
1. カオスエンジニアリングとは
「本番稼働中のサービスにあえて擬似的な障害を起こすことで、実際の障害にもきちんと耐えられるようにしよう」という概念です。障害が発生した場合、複雑なシステムほど、原因がどこにあるのかつきとめにくくなります。そこで、障害を早期に見つけ、被害を最小限に抑える取り組みであるカオスエンジニアリングが重要となります。

2. サイバーセキュリティとの関連性
米国国立標準研究所(NIST)はサイバーセキュリティフレームワーク(CSF)の中で、防御だけではなく、「検知」「対応」「復旧」について、言及しています。これは、「侵入を完全に予防するのは不可能。攻撃は受ける前提で、攻撃からいかに早く復旧するかが鍵」という昨今のサイバーレジリエンスの考えを踏まえたものです。サイバー攻撃を受けた際に、障害の範囲を特定し、早急に復旧するために、カオスエンジニアリングが有効です。

3. 基本手順
カオスエンジニアリングを実行するには、以下の5つの手順が必要です。
3.1 定常状態の定義
システムが通常動作をしていることを示す指標を定義する。このとき、「システム全体としてサービスを正しく提供できているか」を計測できる定量的な指標を定義する。
3.2 仮説の構築
障害時でも定常状態を維持する仮説を構築する。
3.3 変数の注入による実験
サービスを構成するシステムを対照群と実験群にわけ、実験群にのみ、現実世界で起こりうる変数(障害)を注入する。
3.4 検証
実験結果に対して、対照群と実験群の間で定常状態に差異があるかを確認する。
3.5 改善
構築した仮説が正しかったのか、もし正しくないのなら、どこに問題があったのか実験結果から学び、それをシステム改善に活かす。
4. 親和性の高い業界・システム
アマゾン ウェブ サービス ジャパン株式会社主催の「ChaosConf2019 recap」で、カオスエンジニアリングは、以下の業界やシステムと相性が良いと発表があったようです。
【業界】
・ECや金融業界など、可用性が事業の収益に直接的に影響する業界
【システム】
・マイクロサービス
※マイクロサービス:従来のモノリシックサービスとは異なり、DockerやKubernetesを活用し、個々のアプリケーションをなるべく疎結合にする開発手法。これにより、障害からいち早く復旧したり、デリバリの速度を速めることが可能。弊害として、原因がどこにあるのかつきとめにくく、リカバリーの影響範囲がわかりづらくなる。

5. 事例紹介
最後にカオスエンジニアリングを適用している企業を紹介します。
・Netflix
動画配信サービスで有名なNetflix社は、様々なシステム、ゾーン、さらにはリージョン全体がダウンした時に、サービスがどのように振る舞うのかテストしています。AWSのus-east-1リージョン全体で大規模障害が発生した際に、カオスエンジニアリングを実施していたことで、うまく対処できたようです。
・クックパッド
クックパッド社では、マイクロサービス化を進めていました。しかし、マイクロサービス化に伴ってサービス全体の可用性が落ちていました。なぜなら、サービス間の通信回数が増えるに伴って、通信が失敗するおそれのある箇所も増加してしまうからです。この問題に対して、カオスエンジニアリングを適用することにより、対障害性を高めることに成功しています。
・ユーザベース
ユーザーベース社では、自分たちの考えている冗長化が正しく動き続けるかどうか、継続的にチェックするために、カオスエンジニアリングを適用しています。ユーザーベース社では、組織に対して、カオスエンジニアリングを応用し、組織のキーパーソンが抜けたときに、どのような問題が生じるか調査し、レジリエントな組織を目指しているようです。
6. まとめ
カオスエンジニアリングについて、基本概念から事例まで紹介しました。Netflix社の名言として、「障害(failure)を避ける最も良い方法は、継続的に障害を起こ(fail)させること」があるようです。まさしくカオスエンジニアリングを表す言葉ですね。この記事でカオスエンジニアリングについて、少しでも理解を深めて頂けたなら幸いです。
参考文献
・カオスエンジニアリングと聞いてカオスになった人必見 - Qiita?
・カオスエンジニアリングを組織にも適用。アンチフラジャイルなシステムを目指してユーザベースが発見した問題とは? - はてなニュース
・【AWS グラレコ解説】カオスエンジニアリングで本当にカオスにならないための進め方をグラレコで解説 - 変化を求めるデベロッパーを応援するウェブマガジン | AWS
・AWS大規模障害を乗り越えたNetflixが語る「障害発生ツールは変化に対応できる勇気を与えてくれる」 | さくらのナレッジ
・NIST Releases Version 1.1 of its Popular Cybersecurity Framework | NIST
・【レポート】Chaos Engineering が合うもの/合わないもの – ChaosConf2019 recap – | DevelopersIO
・カオスエンジニアリングを導入したクックパッドの挑戦 マイクロサービス化に伴う可用性の低下に対応 - エンジニアHub|Webエンジニアのキャリアを考える!
自己紹介
はじめまして。nakajimeeeと申します。
AI・サイバーセキュリティに関するまとめ記事を発信していきます。
ブログタイトルにもあるように、まとめのまとめなので、3-5分程度でなるべく多くの情報に触れられるような記事を書いていきたいと思います。
最初なので、簡単に自己紹介させてください。
■ 現在の職業
・Slerの営業担当
・サイバーセキュリティやAI/機械学習のソリューションを主に担当
■ 経歴
・2017年3月大学卒業(AI/機械学習系研究室)
・2019年3月同大学院卒業(センサ系研究室)
・2019年4月~現職
・2019年8月~AI/機械学習系ライター
・2019年10月~AI/機械学習の人材育成業務
■ 取得資格
・Certified Information Systems Security Professional (Assosiate)
・情報処理安全確保支援士
・統計検定1級
■ 目標
・1日1記事の執筆
・記事執筆を通して、サイバーセキュリティやAIの重要性を知ってもらう
次回から収集した情報を簡潔に分かりやすく執筆していきます。
是非読んでいただけると幸いです。