最近話題の"Diffusion Model(拡散モデル)"について、簡潔にまとめてみた
OpenAIが先日発表したGLIDEにDiffusion Moldelが使用されているとのことで、最近話題のDiffusion Model(拡散モデル)について、まとめました。
サマリー
・Diffusion Model(拡散モデル)は、元データにノイズが徐々に付加されていき、最終的にガウシアンノイズとなるという前提を置き、その逆のプロセスをモデル化することでデータを生成する。
・GANやVAEよりも高品質の画像を生成することに成功しており、様々な分野への応用が期待される。
生成モデルとは
生成モデルを使用することで、データ(ex. 画像)の生成プロセスをモデル化し、ノイズ等から新たなインスタンスを生成することが可能です。下記の図は、生成モデルによって生成された画像です。もはや本物としか思えないほど、精巧な画像を生成できています。

代表的な手法として、GAN・VAE・Flowがあります。Diffusion Modelはこれらの生成モデルと同等、或いはそれ以上に精巧にデータ生成できることが、昨今の研究で判明しています。
Diffusion Model(拡散モデル)とは
Diffusion Modelはノイズからスタートし、徐々にノイズを除去していくことで、データを生成するモデルです。下記の図では、からスタートし、T回のノイズ除去ステップを踏むことで、顔画像
を生成しています。もちろん、どのようにノイズを除去すればよいのか、言い換えるならば、どのような過程でノイズが付与されたのか、ということが分からなければ、データを生成することはできません。ノイズを付与していく過程をForward diffusion process、除去していく過程をReverse diffusion processと呼びます。以下、この2つのプロセスについて、考えていきましょう。
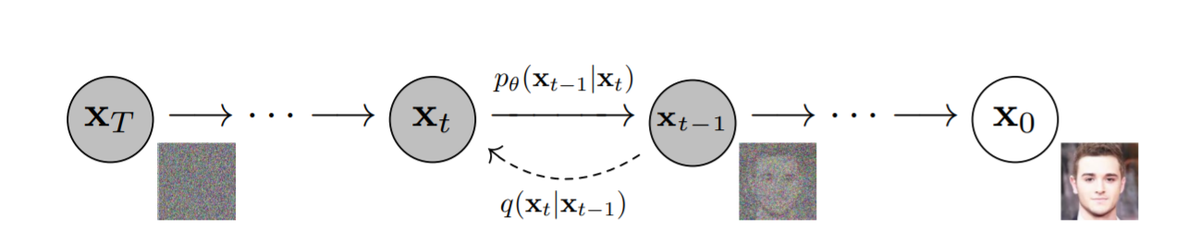
Forward diffusion process
このプロセスは、状態にガウシアンノイズを付与することで、次の状態
に遷移させるプロセスです。つまり、このプロセスはノイズの強さを
とすると、以下のように表現できます。なお、初期状態
は
からサンプルされているとします。
これは、任意のステップの状態
が前の状態
の関数で表現できるということです。つまり、これを
回繰り返すことで、
を初期状態
で表現できます。なお、
と定義しています。
\begin{aligned}
\mathbf{x}_t
&= \sqrt{\alpha_t}\mathbf{x}_{t-1} + \sqrt{1 - \alpha_t}\mathbf{z}_{t-1} & \text{ ;where } \mathbf{z}_{t-1}, \dots \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \\
&= \sqrt{\alpha_t \alpha_{t-1}} \mathbf{x}_{t-2} + \sqrt{1 - \alpha_t \alpha_{t-1}} \bar{\mathbf{z}}_{t-2} & \text{ ;where } \bar{\mathbf{z}}_{t-2} \text{ merges two Gaussians } \\
&= \dots \\
&= \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\mathbf{z} \\
q(\mathbf{x}_t \vert \mathbf{x}_0) &= \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t)\mathbf{I})
\end{aligned}
Reverse diffusion process
ノイズを除去していくプロセスをモデル化できれば、状態からデータを生成できます。つまり、Forward processの逆プロセスである
を表現できれば良いということです。
が十分小さいとすると、
はガウス分布に従います。これをパラメータ
のニューラルネットワーク
で近似します。
は、このままでは非常に扱いにくいので、
で条件付けします。この
もガウス分布に従うと仮定し、平均及び分散を何かしらの形で表現することを目指します。詳細は割愛しますが、ベイズの定理を用いて、平均及び分散は以下となります。
\begin{aligned}
\tilde{\boldsymbol{\mu}}_t &= {\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbf{z}_t \Big)} \\\tilde{\beta}_t &= 1/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) = \frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t \\
\end{aligned}
学習
上記を踏まえて、Diffusion Modelを学習させるために必要な損失関数を考えます。詳細は割愛しますが、クロスエントロピーの最小化、或いはVAEと同様に負の対数尤度の最小化を目指すことで、損失関数は以下となります。なお、はカルバックライブラーダイバージェンスを表しています。
\begin{aligned}
L_\text{VLB} &= L_T + L_{T-1} + \dots + L_0 \\
\text{where } L_T &= D_\text{KL}(q(\mathbf{x}_T \vert \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_T)) \\
L_t &= D_\text{KL}(q(\mathbf{x}_t \vert \mathbf{x}_{t+1}, \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_t \vert\mathbf{x}_{t+1})) \text{ for }1 \leq t \leq T-1 \\
L_0 &= - \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)
\end{aligned}
の最小化は、2つのガウス分布の平均及び分散の差分の最小化と等しくなります。分散を固定のパラメータとすると、ガウス分布の平均の差を小さくするように学習すれば良いことになります。
※分散を固定のパラメータとせず、学習可能なパラメータとしたほうが良い結果が得られるとの実験結果が出ています。詳細はこちらをご覧ください。
応用例
画像生成
DhariwalとNicholはDiffusion Modelを使用して、BigGANと呼ばれる非常に高品質の画像と同等の品質の画像を生成することに成功しています。

条件付き画像生成
DhariwalとNicholらはテキストに沿った高品質の画像を生成することに成功しています。学習データセットに含まれないような画像を生成できており、モデルが人間のように言葉を理解し、それを画像に反映させているようにも見えます。

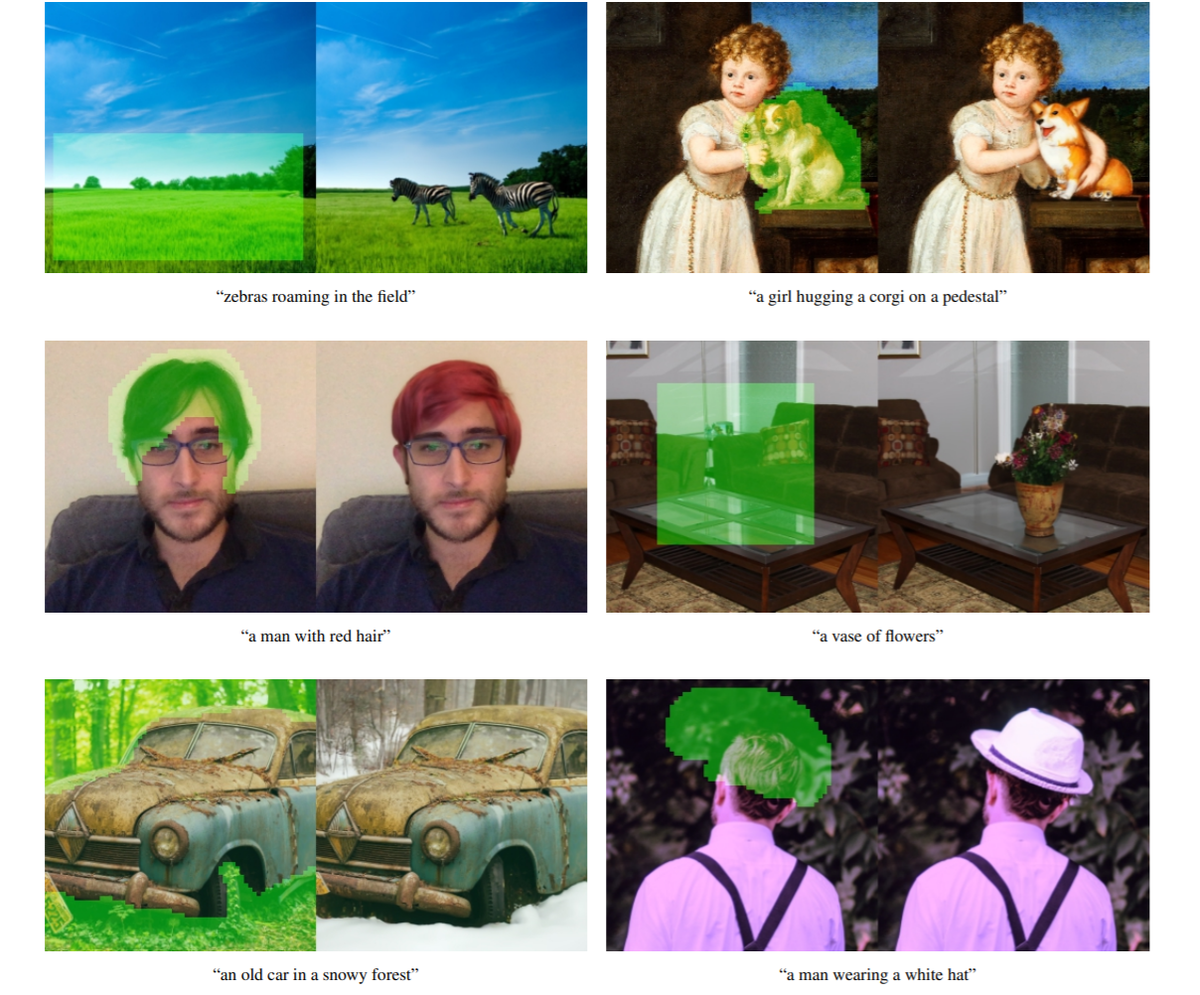
画像変換
DhariwalとNicholらは上記と同様のDiffusion Modelを使用して、指定した個所をテキストに沿って変換するタスクを実施しています。結果を見ると、非常に高精度に画像を変換できていることが分かります。
参考文献
・Inject Noise to Remove Noise: A Deep Dive into Score-Based Generative Modeling Techniques
・Denoising Diffusion Probabilistic Models
・Diffusion Models Beat GANs on Image Synthesis
・GLIDE: Towards Photorealistic Image Generation and Editing with
Text-Guided Diffusion Models